
Towards Attitude Analysis: NLP + Graph Analytics on US News
BSc thesis, ZHAW, 2022. Supervisor: Prof. Dr. Alexandre de Spindler.
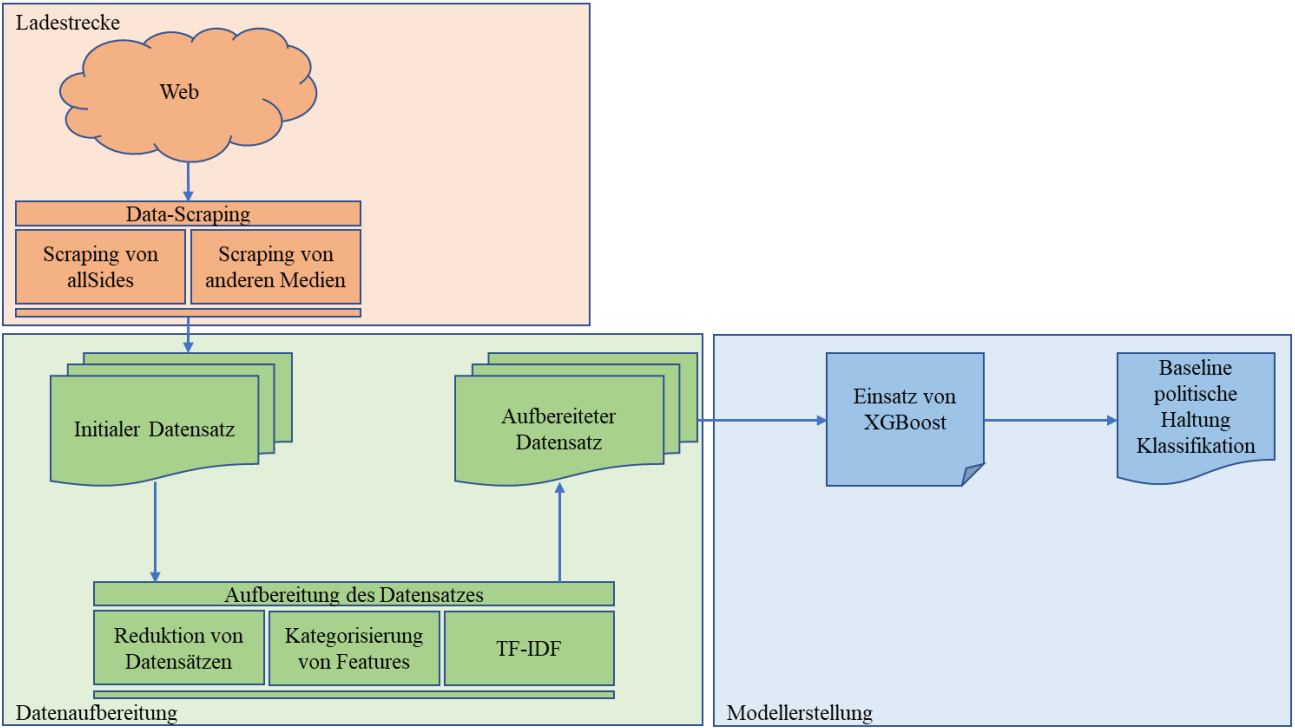
Overview
The project started as fake-news detection and turned into something else after one supervisor meeting. The premise - filter the fake from the real - collapsed under the obvious follow-up: how do you know what's real? "You weren't around for 9/11. How do you know it's real?" "Lots of people say so." "Lots of people, when even the president lies?" After a few rounds of this, the pivot was: forget the truth question, classify the position a text pushes. Liberal or conservative. American outlets, post-COVID, 2021–22 - a window where NLTK and spaCy could still carry most of the work and GPT-3 was a closed beta.
The deliverable: a feasibility study with two layers. A classifier that assigns articles a political leaning, and a Neo4j pipeline that lifts people, topics and sentiment out of those articles into a graph the reporting profile of an outlet can be queried from.
Data
Scraped from AllSides (which classifies outlets as left, center, right) and the outlets themselves. The final corpus held roughly 19,500 articles - ~10,500 right-leaning, ~9,000 left-leaning - across two dozen US outlets. For the focused comparison in the graph step, two outlets stood in for the wings: USA Today (left) and Fox News (right).
| Stage | Count |
|---|---|
| Scraped articles (raw) | ~19,500 |
| Baseline XGBoost sample | 8,000 (RAM-bound at 16 GB) |
| GPT-3 fine-tuning sample | 944 |
Baseline: XGBoost
Outlet, topic keyword, title and TF-IDF article body fed into XGBoost. Balanced 50/50 between left and right to keep class imbalance out of the result. Accuracy landed at 67.3%, and the model leaned left - most articles were classified liberal regardless of source. Good enough to confirm the task was learnable, not good enough to be the answer.
The GPT-3 Detour
OpenAI's GPT-3 was unpublished at the time but accessible by application. Fine-tuned on the 944-article sample, it hit ~90% precision on left/right classification. The thesis reports this and then walks away from it - license costs made it unsuitable for a BSc project. What stayed in the thesis instead was a sentence that aged unusually well:
Once this model ships and goes to market, companies will adopt it and it will change the world.
Written before ChatGPT was published and adapted.
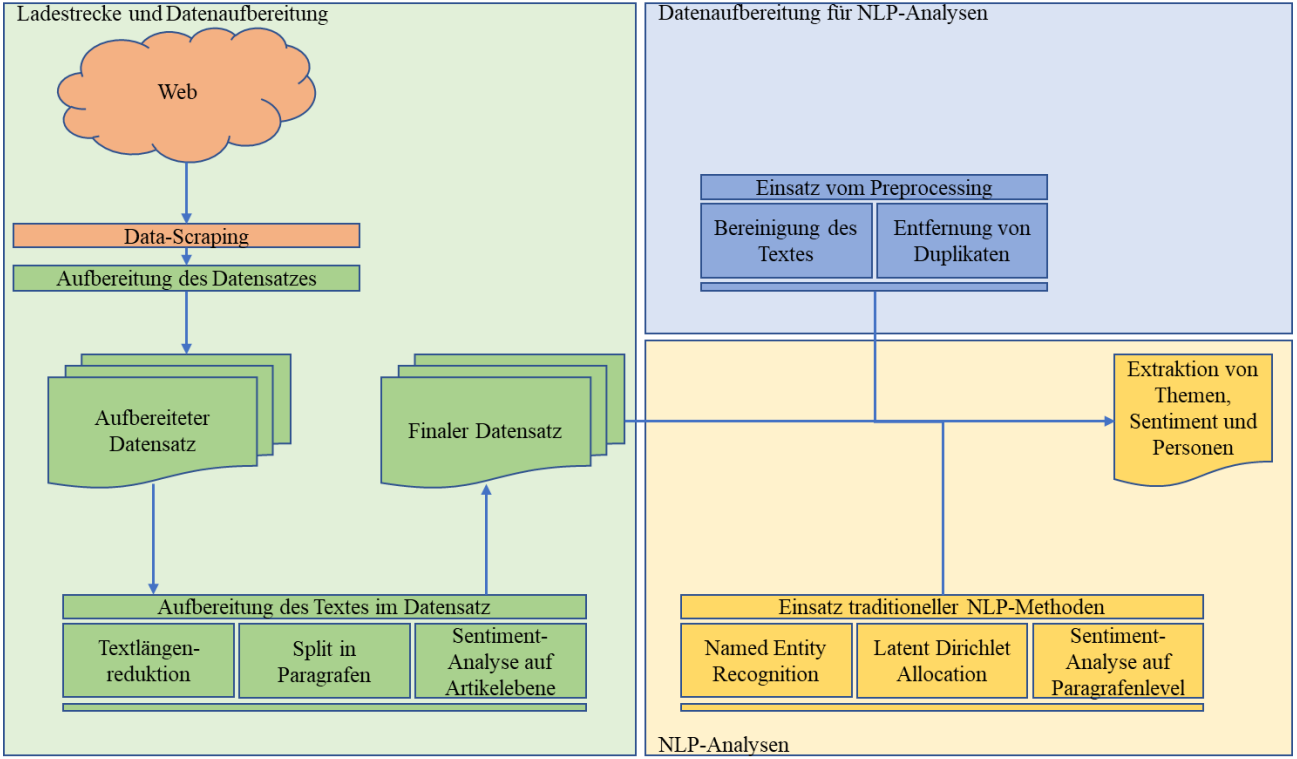
NLP Pipeline (the part the thesis actually shipped)
With GPT-3 set aside on cost grounds, the rest of the project ran on classical NLP. Articles split into paragraphs; NER (spaCy) extracted people, LDA extracted topics, and sentiment analysis ran twice - once per paragraph, once per article - using a Hugging Face model pretrained on financial text (chosen because news prose is closer to neutral reporting than to social media).
System
Outputs from the three NLP heads were joined into a Python converter that wrote nodes (outlets, people, topics) and weighted, signed edges (co-occurrence + sentiment) into Neo4j. Queries ran in Cypher; graph algorithms (Similarity, PageRank, Node2Vec) ran on top to surface reporting patterns no single article showed.
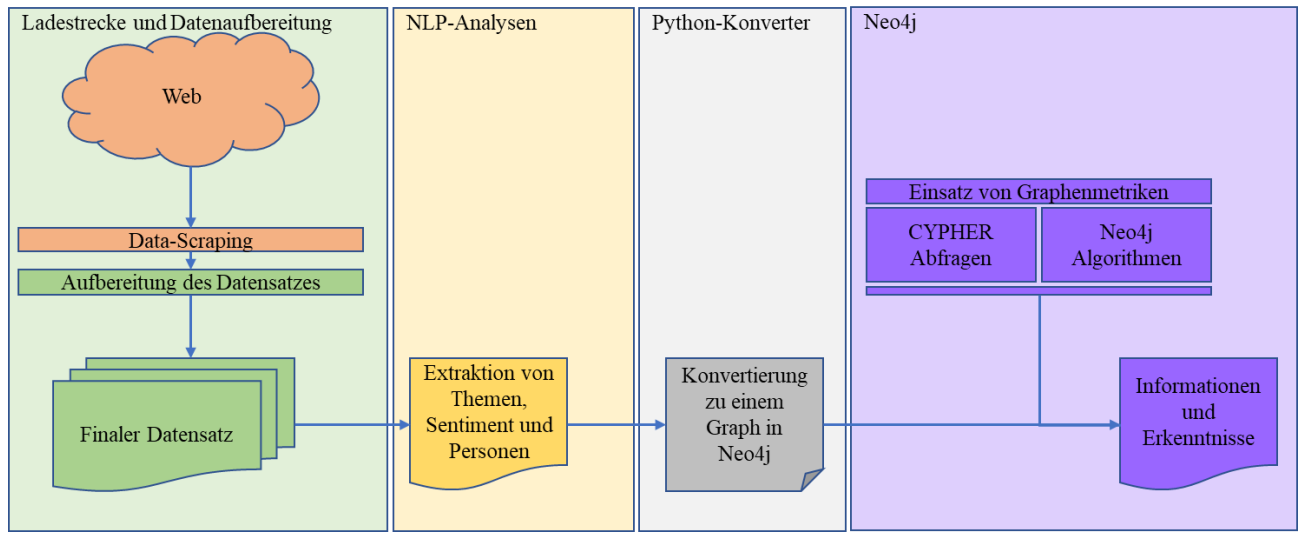
What the Graph Showed
Same three people, two outlets, the same ten topics - sentiment plotted on a radar:
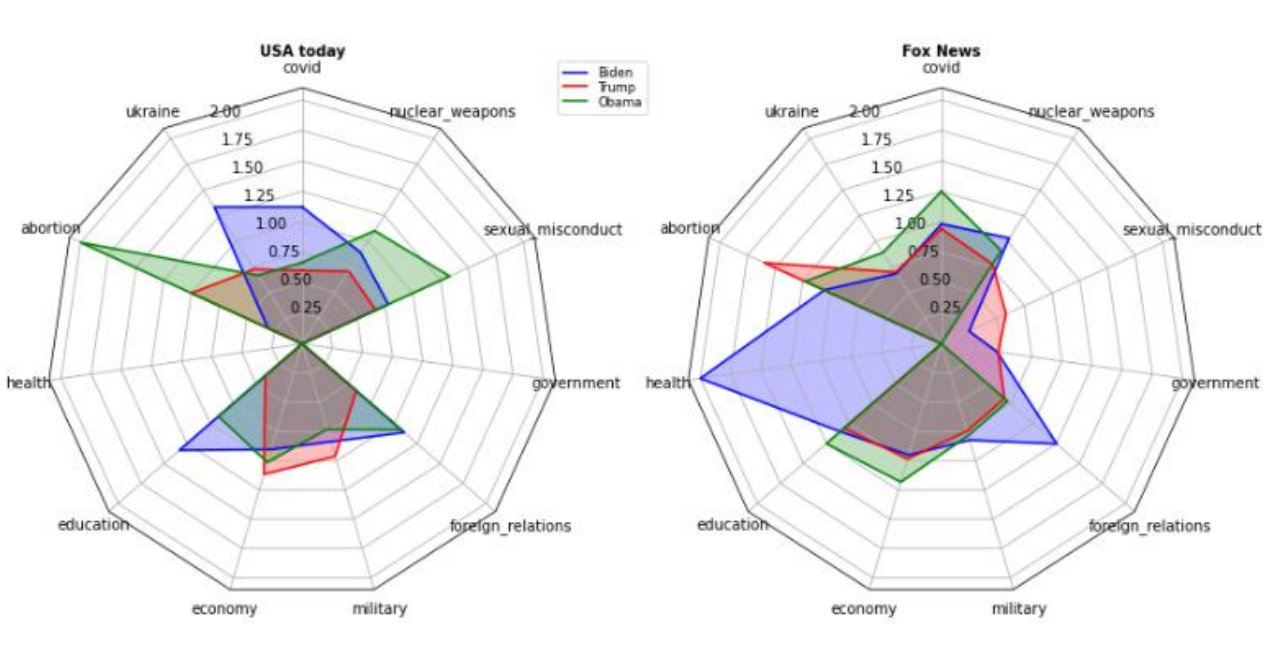
USA Today's three shapes overlap heavily, with isolated spikes (Obama on abortion, Biden on education and Ukraine). Fox News produces the unexpected result of the thesis: Biden, not Trump, is the most positively represented figure across the topic set. Either the sentiment model is being misled by reporting register, or the gap between assumed framing and measured framing is wider than expected. The thesis takes the second reading and concludes that single-outlet reading is the failure mode the pipeline exists to surface.
Learnings
- ·The sentiment surprise is the result. If the radar had matched expectations, the pipeline would only have produced a confirmation. The unexpected Fox/Biden reading is the artefact the rest of the system exists to make visible.
- ·Graph databases earn their keep when the question is relational. "How does outlet X frame person Y on topic Z compared to outlet W" is a query, not a join.