
Project Eros: Locating Yourself in OkCupid
IVDA semester project, UZH, 2022. 🏆 Best Innovation Award (module-internal).
Overview
Given a 59,946-row OkCupid profile dump, the project answers a self-locating question: do I fit into any existing user group on this platform, and how big is that group? A short questionnaire projects the user into a learned feature space alongside the cleaned population. A toggle inverts the question from similarity to dissimilarity. Brushing connects the overview projection to attribute-wise sub-views.
The goal is not matchmaking but legibility: treating the population as the primary object and the user as a point inside it. Built before LLMs were a practical tool for software development.
Data
The raw CSV had three structural problems that defined the preprocessing pipeline:
| Issue | Example | Treatment |
|---|---|---|
| Composite categorical strings | diet = "strictly anything" | Split into category + modifier, label-encoded |
| Multi-value cells | ethnicity = "asian, white" | One-hot encoded |
| Heavy missingness | offspring 59.3%, diet 40.7% | Drop rows after explicit column whitelist |
Result: 842 items, 88 features, heavy reduction by design. The whitelist of columns is parameterised so feature count trades against item count.
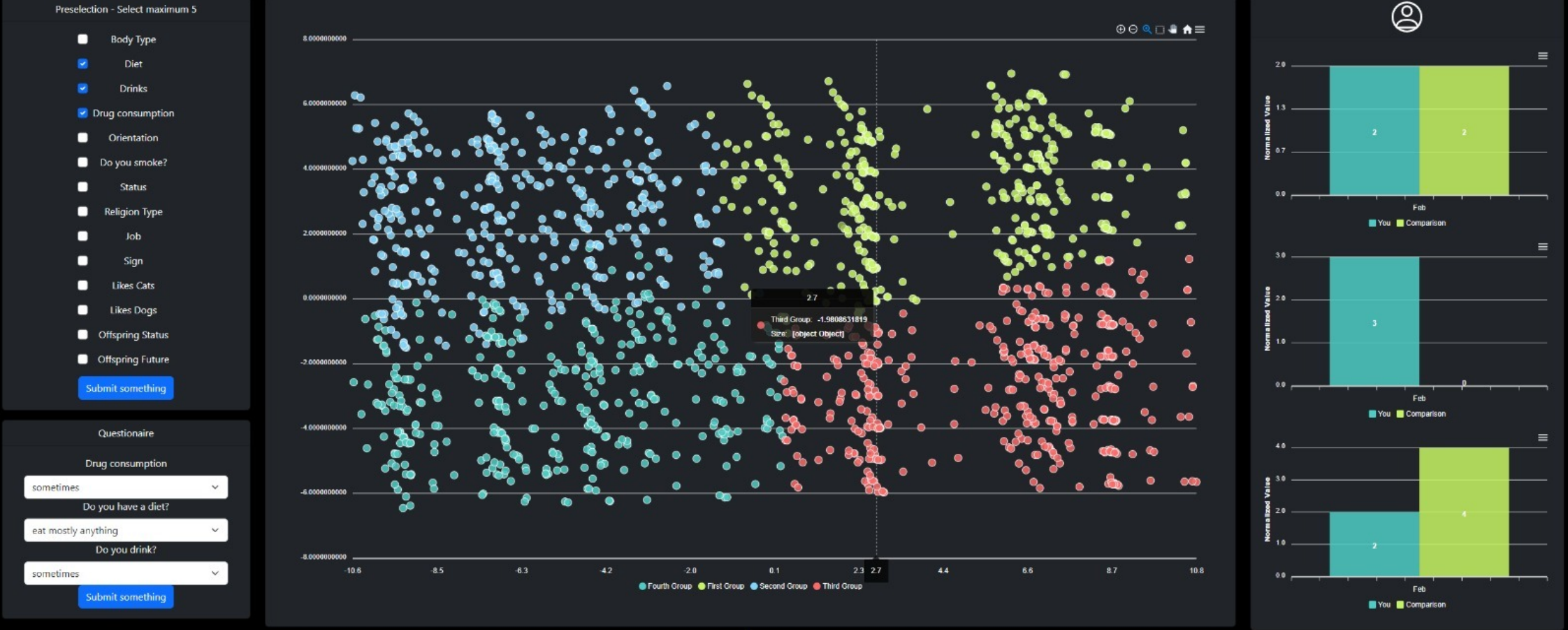
System
The overview is a 2D PCA-style projection of the 88-dimensional feature space. Nodes are profiles; position encodes similarity to the user; colour runs saturated green (similar) to saturated red (dissimilar). The dissimilarity toggle re-runs KNN with inverted ranking and reuses the same visual language. The flow follows Shneiderman's overview first, zoom and filter, details on demand.
Learnings
- ·Mock the model, ship the UI in parallel. Stubbing KNN output with JSON let the frontend mature independently of a backend that integrated late.
- ·Cleaning is the project. The drop from 59,946 to 842 items is the design decision, not a data flaw.
- ·Linked views beat dense views. The original UpSet + Venn plan was abandoned after midterm feedback on Venn readability. The scatter + linked sub-views pivot was the correct call.
- ·Mixed-type KNN is a methodological soft spot. Euclidean distance over one-hot, label-encoded, and standardised columns assumes comparable contributions; it does not.
Future Work
- ·Gower or per-column-weighted distance to fix the mixed-type KNN issue.
- ·Cluster summaries alongside the overview; the user sees which points are close, not what defines the cluster.
- ·Threshold controls for filter density.